OmniMouse: Scaling properties of multi-modal Brain Models
Konstantin Willeke*, Polina Turishcheva*, Alex Gilbert *, et al.
Stanford University, University of Göttingen
Scaling data and artificial neural networks has transformed AI, driving breakthroughs in language and vision. Whether similar principles apply to modeling brain activity remains unclear. We train multi-modal, multi-task models on >2.3 million neurons from 73 mice (150B+ neural tokens), supporting neural prediction, behavioral decoding, and neural forecasting flexibly at test time. OmniMouse achieves state-of-the-art performance across nearly all evaluation regimes. Performance scales reliably with more data, but gains from increasing model size saturate, inverting the standard AI scaling story: brain models remain data-limited despite vast recordings.
OmniMouse is trained on one of the largest single-neuron datasets ever assembled: 2,282 imaging planes from 78 animals and 328 sessions, containing >2.3 million segmented neurons, collected from the lab of Prof. Andreas Tolias, with more datasets being released in the near future. Recordings are of excitatory neurons in visual cortex, acquired with wide-field two-photon calcium imaging at 6–14 Hz in awake, head-fixed, behaving mice. The explorer below lets you browse the full collection. Filter by animal, session, or cortical depth, and switch between average images, correlation maps, and segmentation masks.
Figure 1. Dataset explorer. Each tile is one scanning plane. Toggle between average images, correlation maps, and segmentation masks; arrange by animal, scan, or cortical depth; or zoom into a single field of view.
Motivation
Scaling data and artificial neural networks has transformed AI, driving breakthroughs in language and vision. Whether similar principles apply to modeling brain activity remains unclear. Neural recordings are costly, and compared with the internet-scale corpora used in language and vision, available neural datasets are much smaller, more fragmented, and less diverse.
The mouse visual cortex, with large-scale neural datasets and standardized benchmarks, offers a natural setting to investigate this. Prior work has focused on isolated modalities, a single predictive task, or omitted stimulus and behavioral information. As a result, the field has had intuitions about scaling but little direct evidence of how data size, model size, and task coverage interact at realistic scales.
We introduce OmniMouse, a multi-modal, multi-task architecture for modeling neuronal activity in the mouse visual cortex. Unlike prior models that are typically restricted to a single modality, OmniMouse combines single-neuron tokenization, video encoding, and behavioral decoding into a unified architecture. Flexible masking enables arbitrary combinations of neural forecasting, stimulus-conditioned response prediction, sub-population prediction, and behavioral decoding, which makes it possible to study how performance depends jointly on data, model, and task structure.
Figure 2. Overview. OmniMouse unifies neural prediction, behavior decoding, and forecasting into one model. Scaling model size on 150B+ neural tokens shows saturation; scaling data size, in contrast, continues to improve performance across model sizes.
The OmniMouse Model
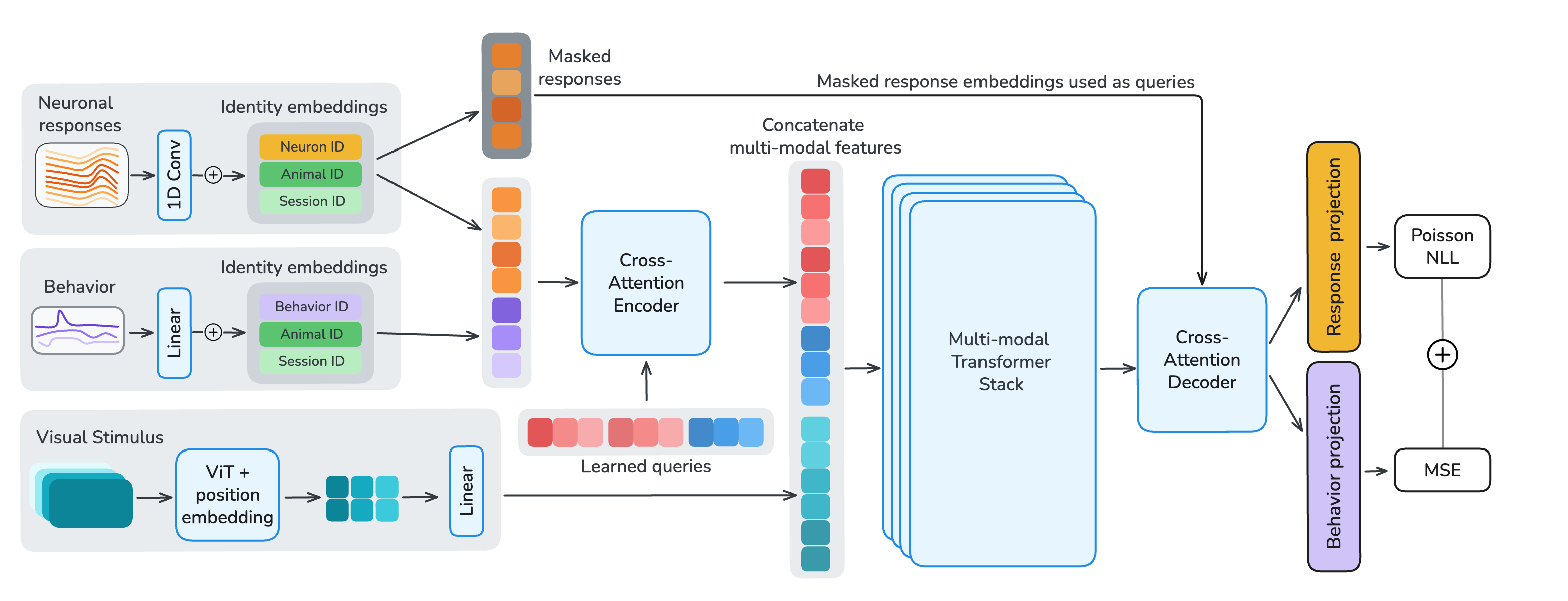
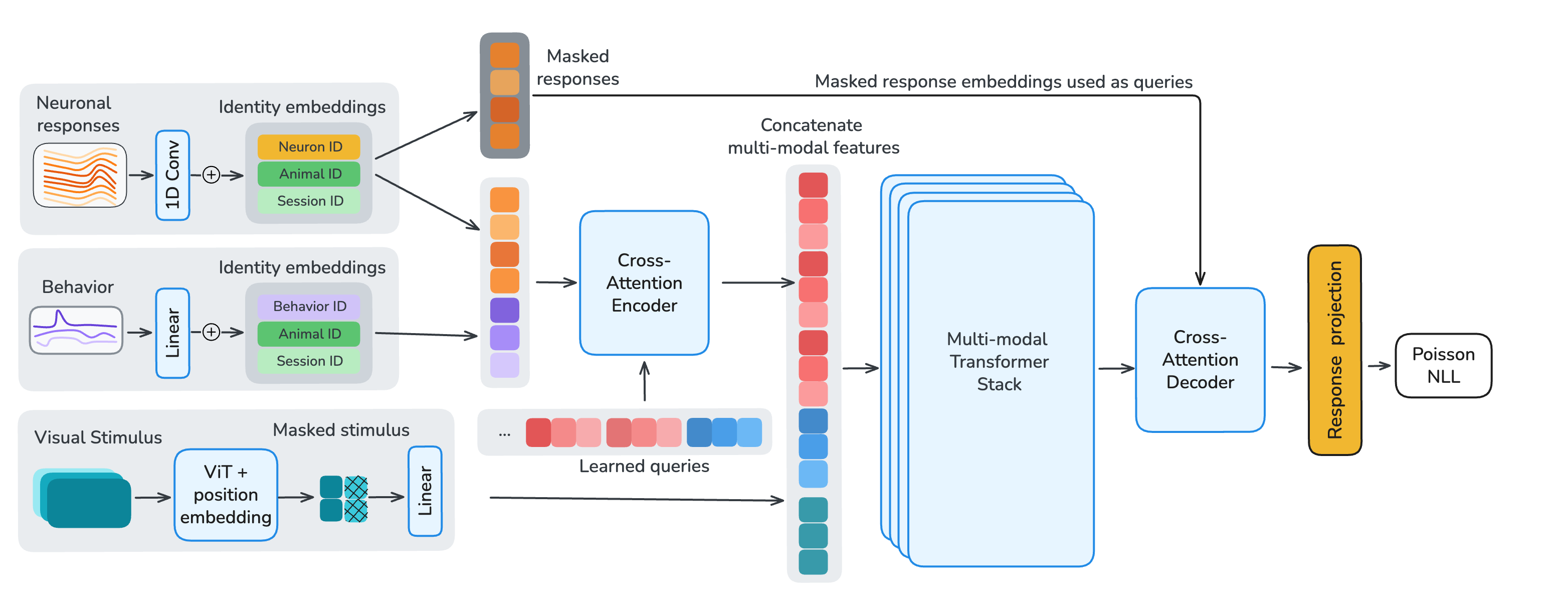
The input to OmniMouse is a temporal chunk of multi-modal data: neural responses, stimulus frames, and five behavioral traces (pupil x/y, pupil size and its derivative, running speed), all time-aligned at their respective sampling rates. This chunk is paired with a masking configuration specifying which samples from each modality are encoded (unmasked) and which serve as reconstruction targets, so training and evaluation share the same interface.
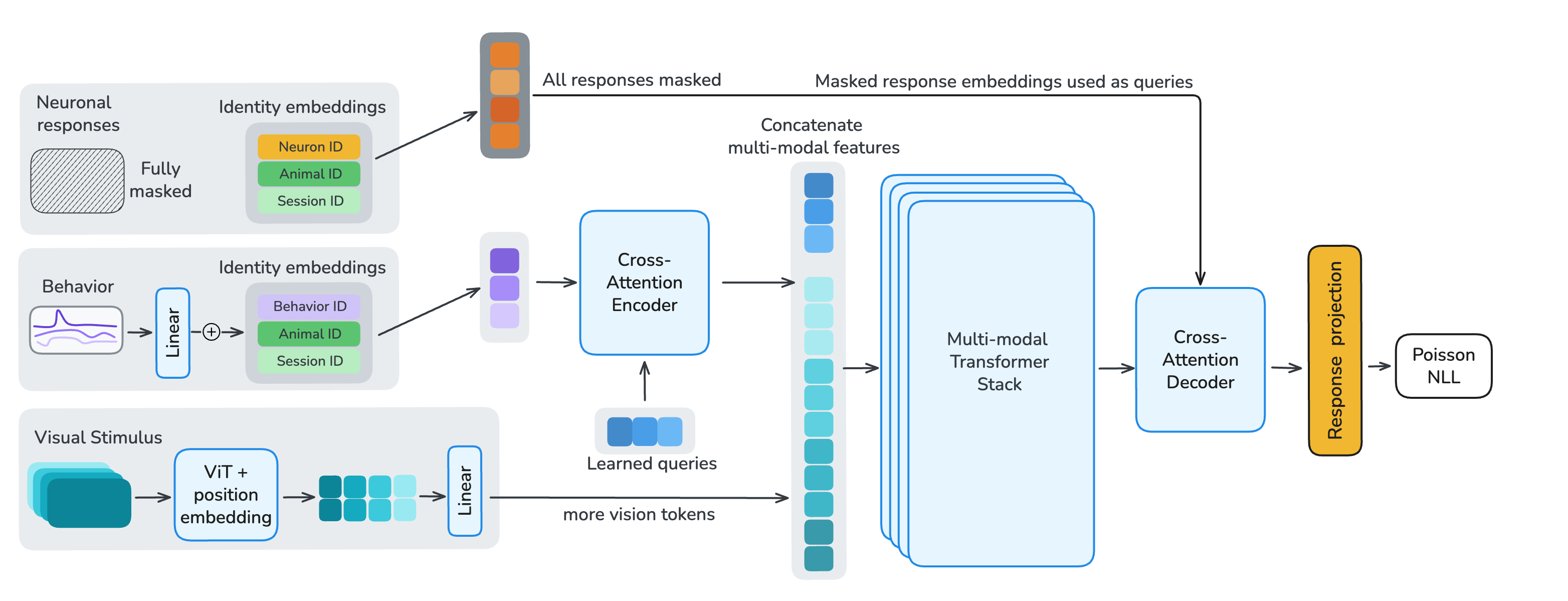
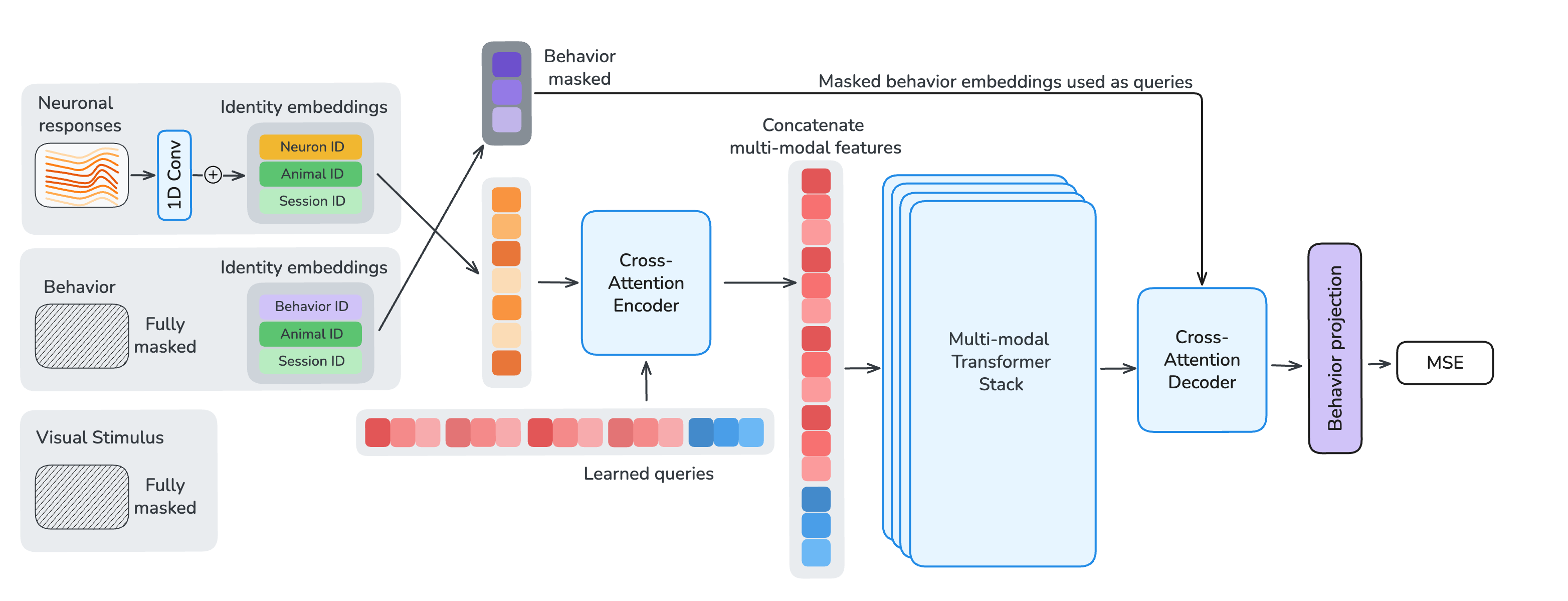
To enable per-neuron, per-sample masking, we apply a strided 1D convolution along the temporal dimension of each neuron's calcium trace. Each token is augmented with learned identity embeddings for its neuron, session, and animal. To decouple per-neuron parameter count from model size, embedding tables have a fixed dimension with a shared linear projection into model space. Visual stimuli are encoded with the first ten layers of a randomly-initialized Hiera vision transformer. Behavioral traces are either fully provided as encoder input or fully masked and used as decoder reconstruction targets.
After tokenization, we process the multi-modal embeddings in three stages. (1) A cross-attention encoder with learned latent queries compresses unmasked neuronal and behavioral tokens into a fixed-length latent sequence, using local sliding-window attention with global register tokens to preserve long-range information flow. (2) A multi-modal fusion stack integrates these latents with Hiera video features through transformer layers that interleave sliding-window and global self-attention at a 5:1 ratio. (3) A shared cross-attention decoder reconstructs target neuronal responses and behavioral traces from the fused representation. All transformer layers use 1D-RoPE computed from each token's timestamp, encoding relative timing both within and across modalities.
turning the
We train with 119 structured masking configurations, including our core evaluation tasks (forecasting, population prediction, stimulus encoding, and behavioral decoding) as well as numerous systematic variations that reduce or combine context across modalities. The same model therefore handles all tasks without task-specific heads. At evaluation time we can also probe mask combinations the model has never seen.
(interactive demo)
Overview
Neural Response Masking
Behavior Masking
Visual Stimulus Masking
Figure 3. Model and masking. Single-neuron, single-time-chunk tokenization feeds a cross-attention encoder, a multi-modal fusion stack with Hiera video features, and a shared cross-attention decoder. Response, behavior, and stimulus masks define which samples are inputs versus reconstruction targets.
Dataset
We train OmniMouse on more than 3 million neurons from the visual cortex of 73 mice across 323 sessions, totaling over 150 billion neural tokens. The mice were presented with naturalistic images sampled from ImageNet, videos sampled from cinematic movies and the Sports-1M dataset, and parametric stimuli including static and drifting Gabors, directional pink noise, flashing Gaussian dots, random dot kinematograms, and model-generated stimuli. We recorded five behavior variables throughout every session: running speed, pupil x and y position, pupil dilation, and its derivative.
For training we reconstruct the visual stimulus presented throughout the entire recording, including blank periods between stimulus blocks, so the model sees a continuous stream rather than isolated trials. We downsample behavior to 20 Hz, visual stimuli to 30 Hz, and linearly upsample neuronal responses to 30 Hz to be comparable to the SENSORIUM 2023 benchmark. All token counts refer to the number of samples before upsampling, to avoid artificially inflating the dataset size.
Interactive data and prediction viewer
Step one level deeper and watch the model run. On the left, pick a masking configuration. Toggle video and behavior as inputs, and choose how many samples of causal context and how many other population neurons the model can see. On the right, scrub through a 9-second clip and compare OmniMouse’s predictions against the measured responses (or behavior) sample by sample. The same OmniMouse-80M checkpoint is used for every configuration, so sweeping the sliders is a genuine in-silico experiment.
Figure 4. Interactive prediction viewer. The schematic on the left reflects the current masking configuration for neuronal responses, beahvior, and visual stimulus. For each masking configuration, the same neurons are the reconstruction target. The hatched block represents the full neuronal population with its causal and population context regions. The plot on the right shows one 9-second clip for the selected neuron or behavior channel: gray traces are ground truth outside the active 2 s window, black traces are ground truth inside it, and the bold orange/purple line is the OmniMouse prediction over the reconstructed window (1 s for responses, 2 s for behavior). The bottom-right badge reports the Pearson correlation of prediction against ground truth. Switch to the Population view on the response side to see all 35 target neurons stacked in a time-offset layout, or toggle All neurons when predicting behavior to use the full neuronal population as context. Every combination reruns against the stored OmniMouse-80M predictions, so you can see directly how stimulus, behavior, and population size each contribute to performance.
Results
State-of-the-art performance. OmniMouse outperforms all baselines across six evaluation regimes for both response prediction and behavior decoding, and sets a new state of the art on the Sensorium 2022 and 2023 competitions. These gains are not simply due to training on more data: in data-matched comparisons, where OmniMouse and baselines are trained and evaluated on identical datasets, our model outperforms strong specialized methods across all tasks except decoding of running speed. The architectural and masking design of OmniMouse provides advantages independent of data scale.
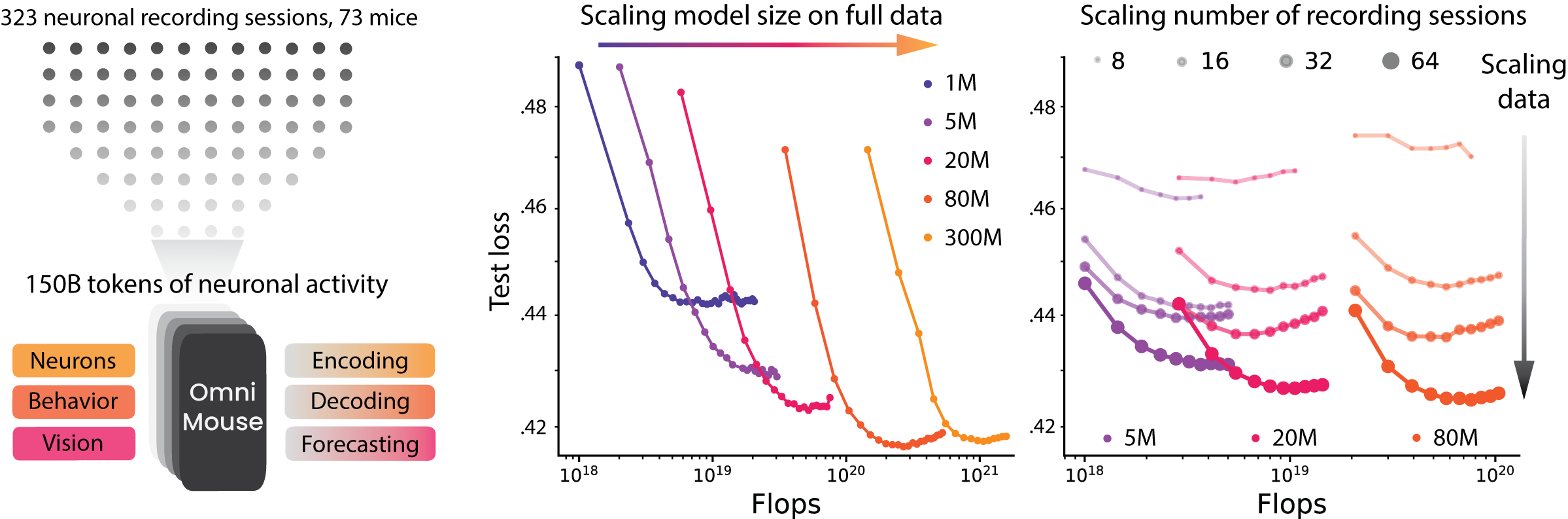
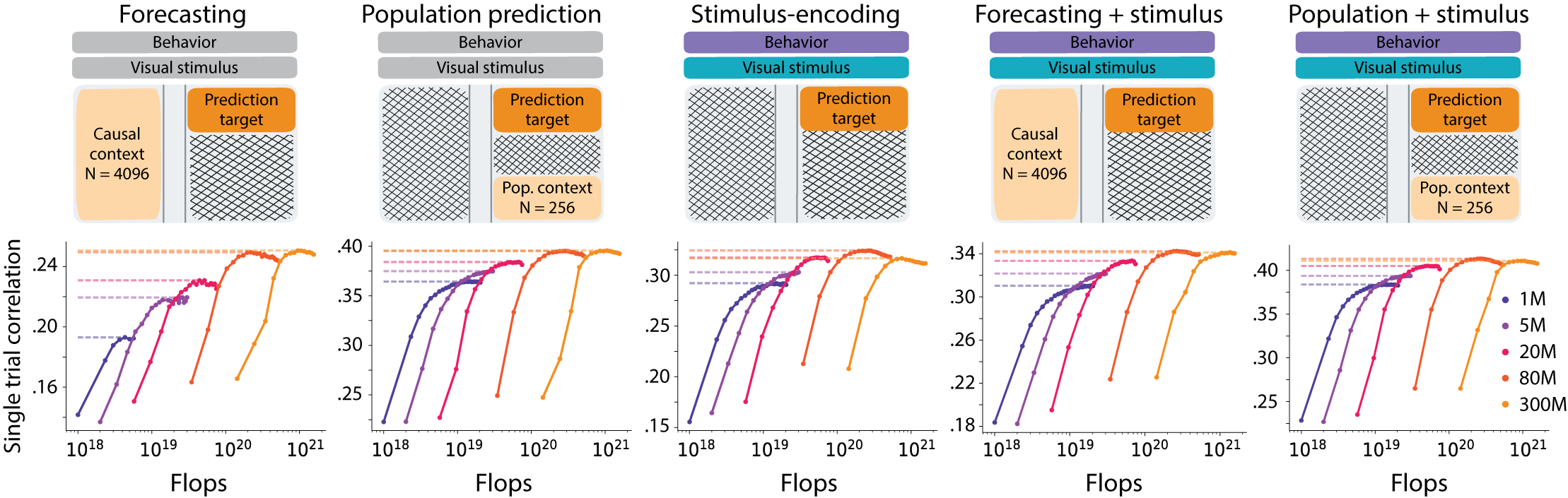
Model scaling saturates. We trained models from 1M to 300M parameters on all 323 sessions, tracking both test loss and single-trial correlation as a function of total compute across five response masking strategies. Performance improved across all neuronal prediction tasks as model size increased up to 80M parameters. Beyond this point, gains were minimal, as loss curves saturated or overfit. Current models at this data scale are data-limited rather than compute- or parameter-limited; the architecture already has enough capacity to absorb the signal the recordings carry.
Figure 5. Task-specific performance gains with model scaling. Top: mask per task. Middle/bottom: test loss and single-trial correlation as a function of compute. Gains level off once models pass ~80M parameters.
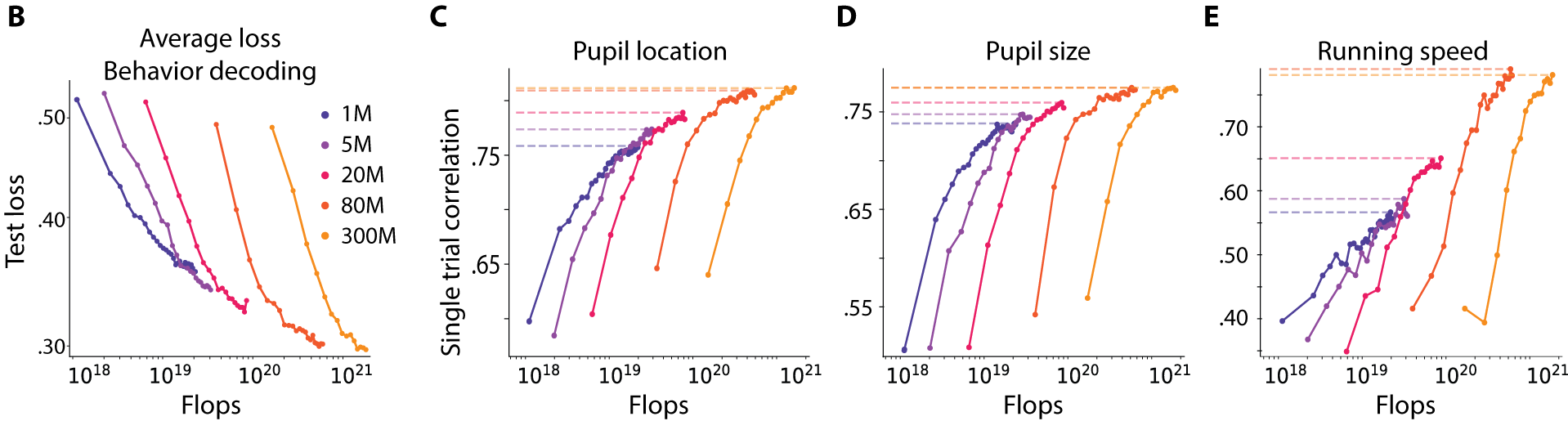
Behavior decoding scales the most. Across decoding of gaze position, pupil size, and running speed, performance improved smoothly with compute budget, reminiscent of classic scaling-law behavior. Larger models consistently achieved higher single-trial correlations, with only a faint indication of saturation at the largest scale tested.
Figure 6. Behavior decoding scales with model size. Per-variable performance for gaze, pupil size, and running speed continues to improve across the full compute range we tested, with no clear saturation.
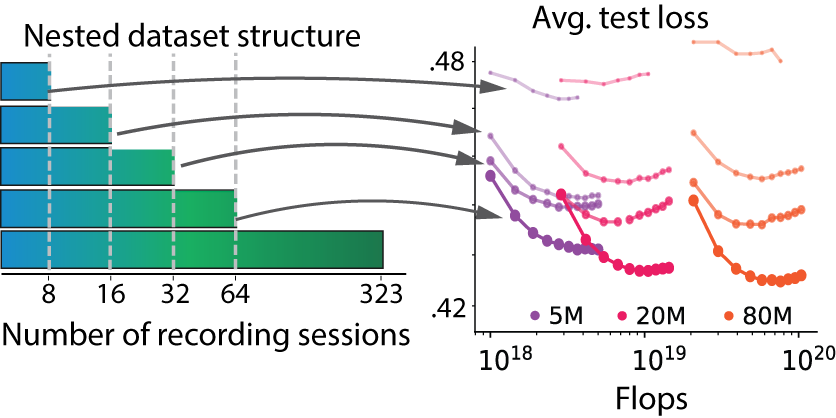
Data scaling works. Scaling the dataset tells the opposite story. We trained 5M, 20M, and 80M models on nested collections of 8, 16, 32, 64, and 323 sessions, such that the larger collections are supersets of the smaller ones, and tested on the same held-out mice in every case. In all cases, performance improved with the number of sessions, exhibiting predictable data-scaling trends. Larger models consistently benefited more from additional data, and the performance gap widened as the dataset increased in size: the signature of a data-limited rather than capacity-limited system.
Figure 7. Data scaling. Nested training collections from 8 to 323 sessions. Performance improves monotonically for every task and every model size, and larger models pull further ahead as the dataset grows.
An inverted scaling story. Together, these results invert the standard AI scaling story. In language and computer vision, massive datasets make parameter scaling the primary driver of progress, whereas in brain modeling, even in the mouse visual cortex, models remain data-limited despite vast recordings. The bottleneck is not compute; it is data: more diverse stimuli, more varied tasks, more animals, and richer behavior.
Benchmarks
Results in bold indicate the best score per task in either the data-matched condition (8 sessions, top) or when using the full dataset (323 sessions, bottom).
Model
Neuronal Activity Prediction
Behavior Decoding
Task
Forecasting
Forecast + Stimulus
Population
Pop. + Stimulus
Average
Gaze
Pupil
Running
Neural context
✓ past
✓ past
✓ subset
✓ subset
✓ all
✓ all
✓ all
✓ all
Visual stimulus
✕
✓
✕
✓
✕
✕
✕
✕
Data-Matched
MtM
0.12
×
0.07
×
×
×
×
×
Latent Model
×
0.18
×
0.16
×
×
×
×
CEBRA
×
×
×
×
0.53
0.52
0.55
0.51
POYO+
×
×
×
×
0.55
0.56
0.63
0.47
OmniMouse-5M
0.18
0.25
0.25
0.27
0.59
0.68
0.66
0.44
Full Dataset
OmniMouse-1M
0.18
0.31
0.27
0.35
0.68
0.75
0.73
0.55
OmniMouse-5M
0.22
0.32
0.28
0.35
0.69
0.76
0.74
0.57
OmniMouse-20M
0.23
0.33
0.29
0.37
0.75
0.78
0.75
0.73
OmniMouse-80M
0.25
0.34
0.29
0.37
0.77
0.80
0.76
0.75
OmniMouse-300M
0.25
0.34
0.30
0.37
0.76
0.80
0.76
0.73
× Model does not natively support this task
Table 1. Baseline comparisons. Single-trial correlation on the same held-out evaluation mice. Bold marks the best score per task within the data-matched block (top, 8 sessions) or the full-data block (bottom, 323 sessions). × indicates that a baseline does not natively support that task.
In-silico neuroscience
The ability to flexibly control and combine different sources of context within a single model opens an exciting avenue for future study, enabling precise quantification of how each factor shapes neural variability and their interactions across brain areas, stimuli, and behavioral states.
(interactive demo)
Neurons in context: 2048
016326412825651210242048
Figure 8. Left: model input masking that defines each condition. Right: single-trial correlation on the entire evaluation set between predicted and measured neural responses as a function of population context size, for the four combinations of available model inputs. The same OmniMouse-80M checkpoint is used for every point; performance scales smoothly with added context along every axis. Toggle whether the model sees the visual stimulus and/or behavior, and vary how many other neurons from the same population are provided as context.
Conclusions
OmniMouse is a multi-modal, multi-task model of mouse visual cortex that jointly integrates neural activity, video stimuli, and behavioral traces within a single unified architecture. Trained on one of the largest single-neuron datasets to date, it outperforms strong specialized baselines on neural response prediction, activity forecasting, and behavioral decoding. The breadth and scale of both model and dataset enable a systematic study of scaling behavior in single-neuron brain models.
Our motivation for studying scaling laws is practical: if brain models are to become foundation models for neuroscience, it is essential to ask whether current data can sustain scaling. We find that performance saturates with model size, suggesting data, not compute, as the limiting factor. Even in the relatively simple mouse visual system, richer tasks, more varied stimuli, and larger-scale recordings are needed to support continued scaling.
The observation of systematic scaling raises the possibility of phase transitions in neural modeling, where larger and richer datasets might unlock qualitatively new capabilities, paralleling the emergent properties seen in large language models. By analogy, richer neuroscience data may similarly unlock new capabilities in brain models, revealing deeper principles of neural computation. OmniMouse's unified, maskable design is one step toward that regime.
Citation
@inproceedings{
willeke2026omnimouse,
title={OmniMouse: Scaling properties of multi-modal, multi-task Brain Models on 150B Neural Tokens},
author={Konstantin Friedrich Willeke and Polina Turishcheva and Alex Gilbert and Goirik Chakrabarty and Hasan Atakan Bedel and Paul G. Fahey and Yongrong Qiu and Marissa A. Weis and Michaela Vystr{\v{c}}ilov{\'a} and Taliah Muhammad and Lydia Ntanavara and Rachel E Froebe and Kayla Ponder and Zheng Huan Tan and Emin Orhan and Erick Cobos and Sophia Sanborn and Katrin Franke and Fabian H. Sinz and Alexander S. Ecker and Andreas S. Tolias},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=mEw4lhAn0F}
}